Welzijn.AI [ STRIPA | DEDUCE | SNPcurator ]
Welzijn.AI is a new digital solution for continuously monitoring the mental wellbeing in the vulnerable elderly. Currently in the form of a mobile app, its ultimate aim is to be embedded within a furry cat toy through a speech-only interface. The NadinaHealth AI virtual assistant is an implementation tailored for geriatric assessments support, in a collaboration with LUMC Geriatrics. [ NadinaHealth v1 AI demo video in English ]
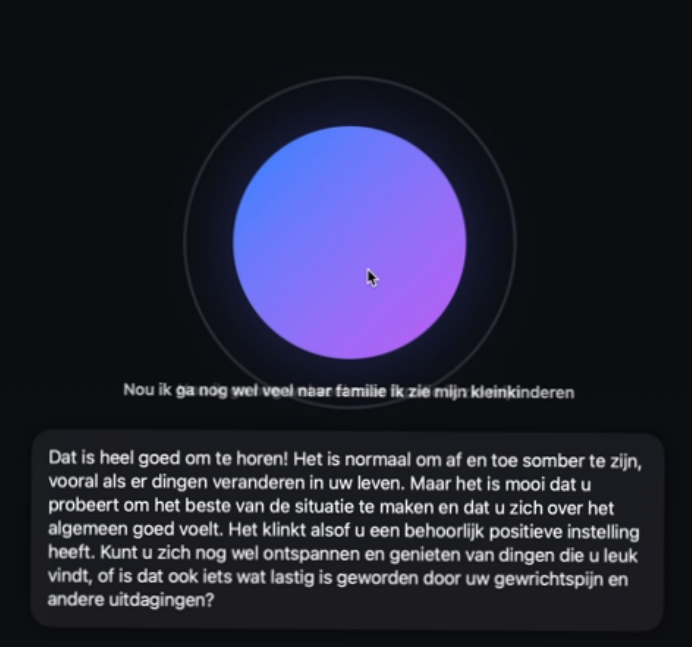
Additionally, we have developed various alternative prototypes to assess the different technological LLM approaches. For example, Roderick Leito investigated RASA's CALM approach for administering the EQ-5D: video.
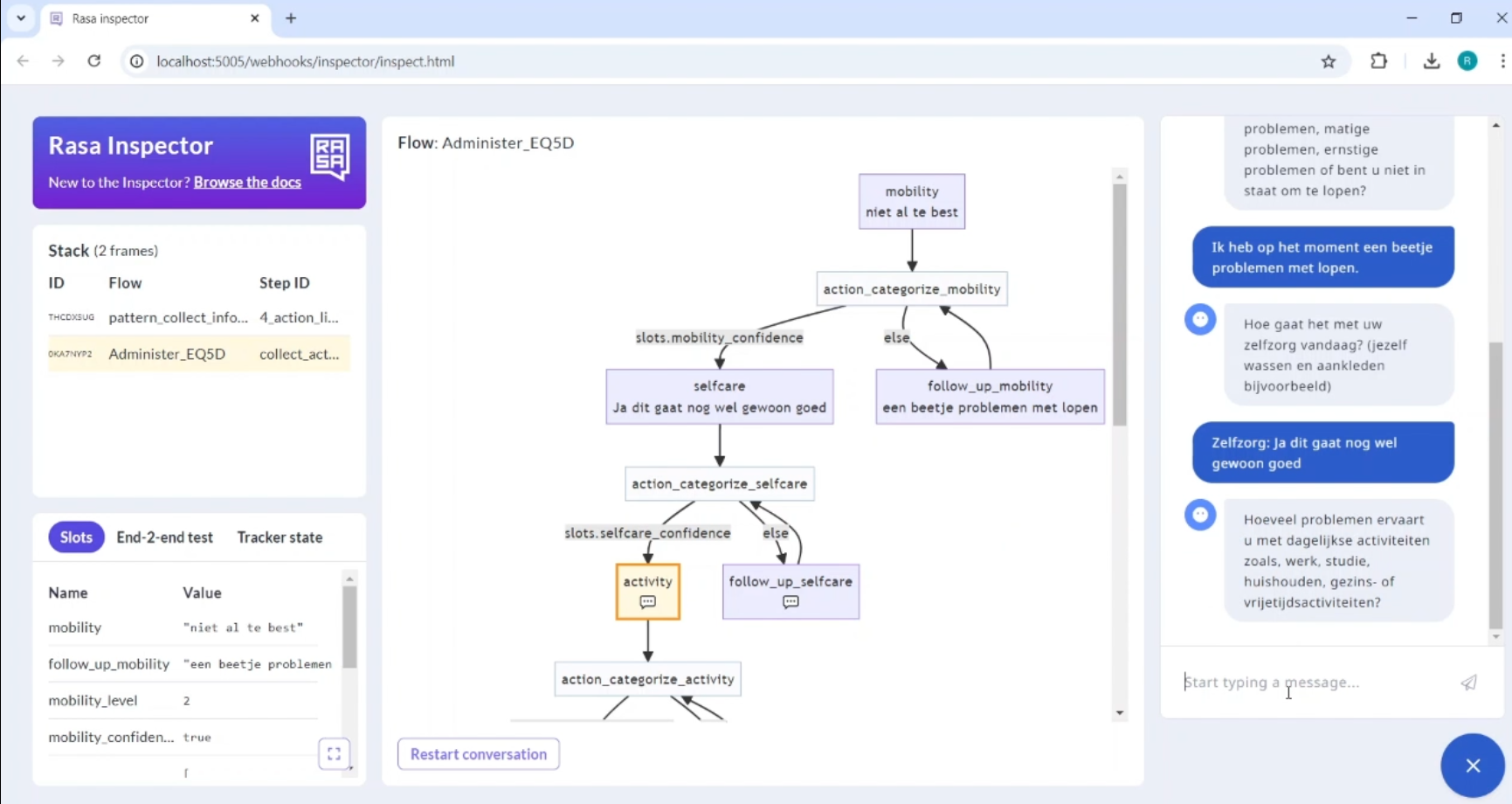
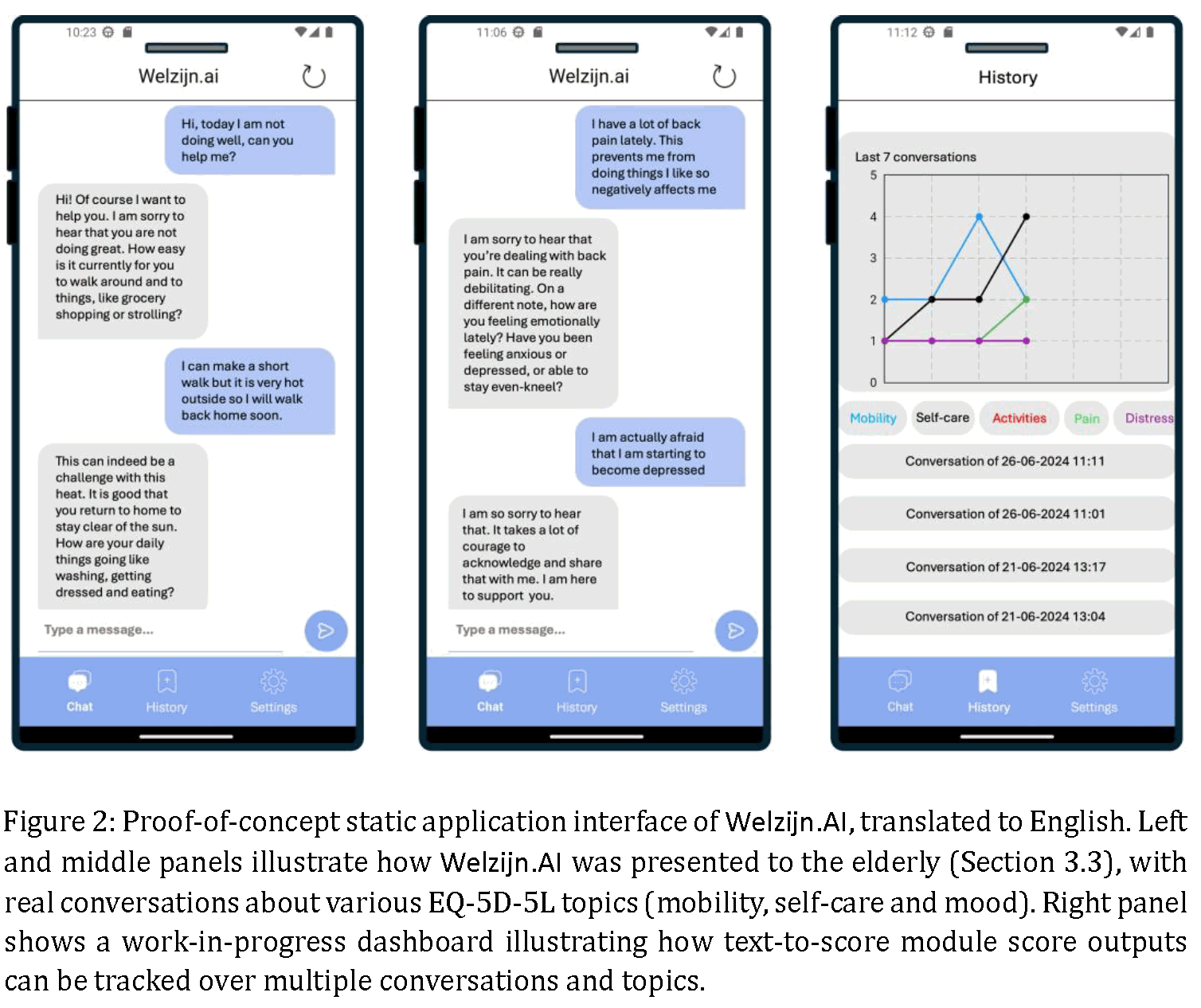
Another extended English demo video of Wellbeing.AI with explanatory captions has also been prepared by Bram.
STRIPA [ DEDUCE | SNPcurator | Welzijn.AI ]
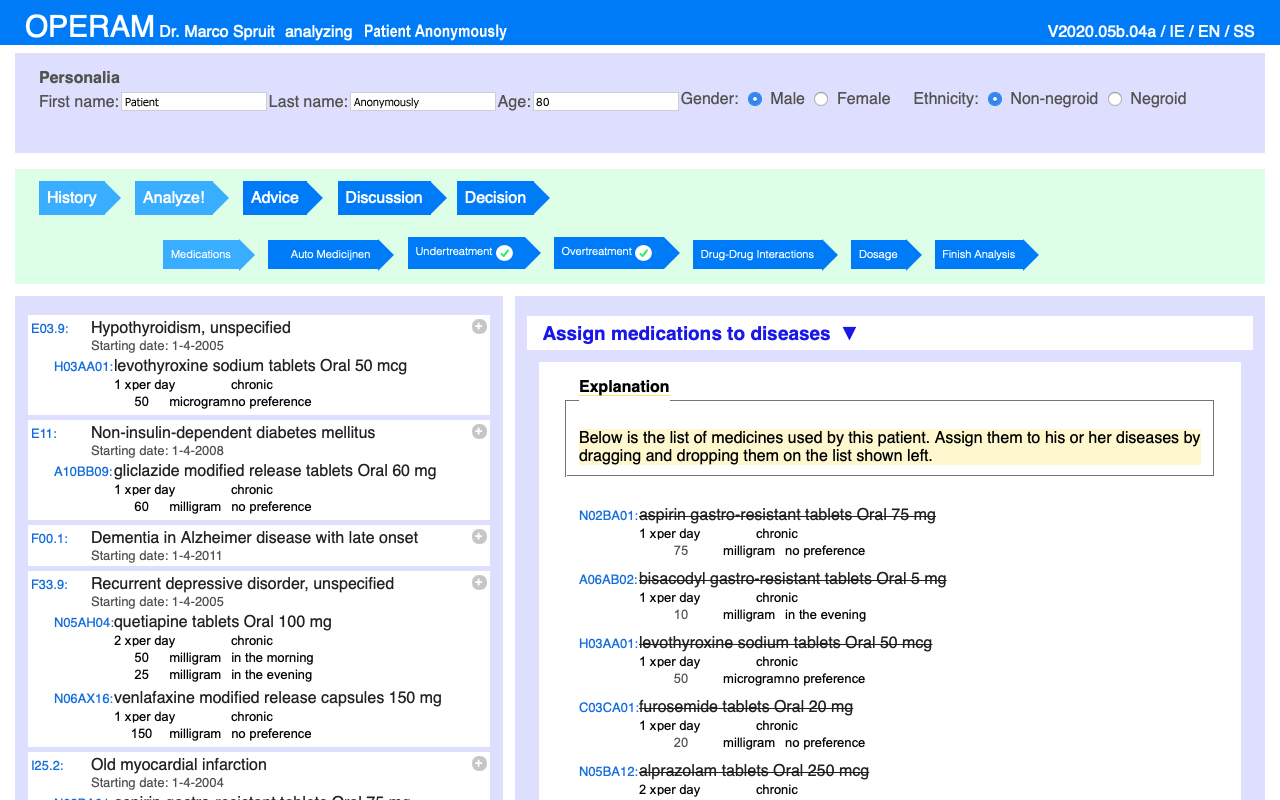
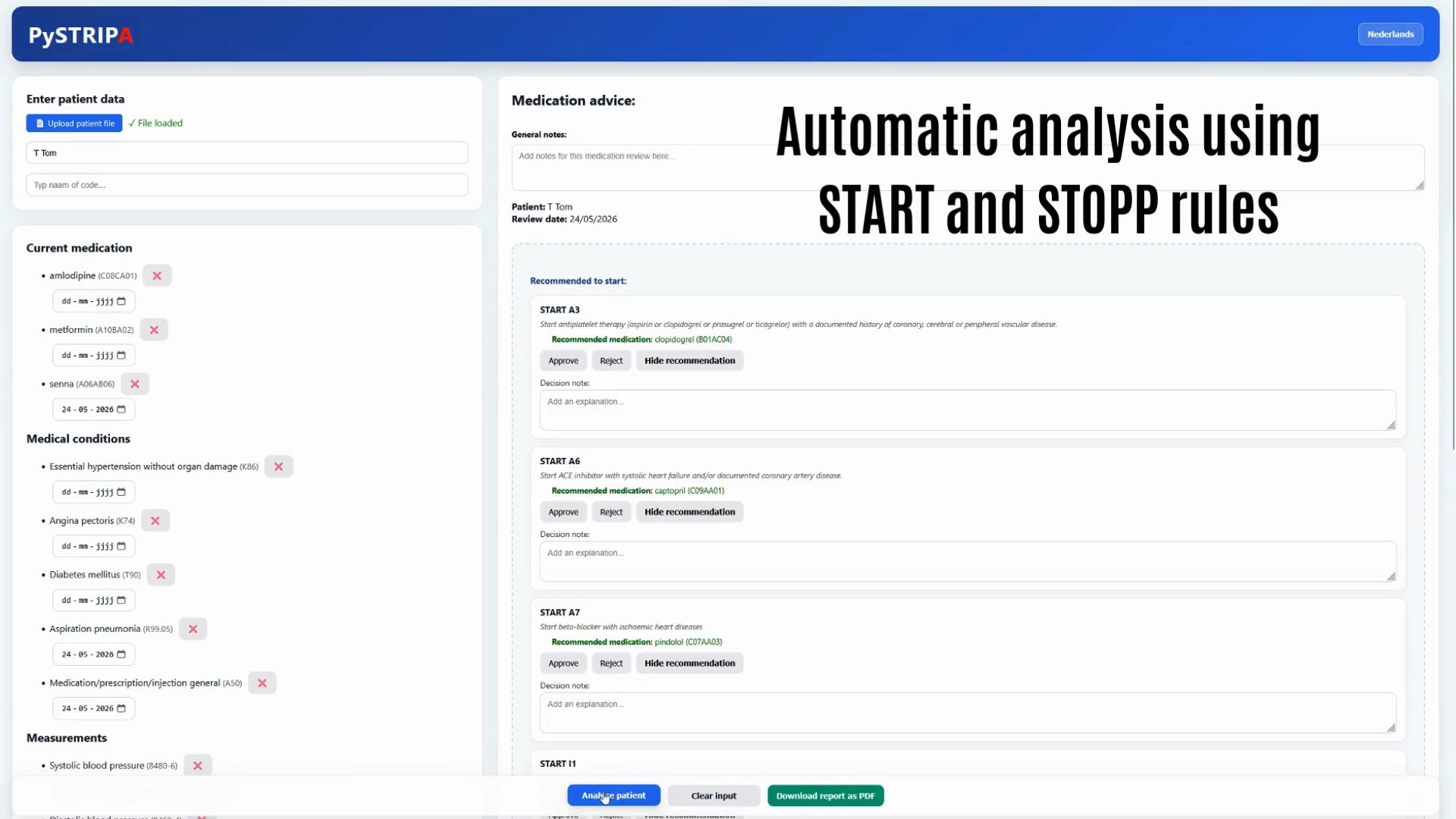
The STRIP Assistant (STRIPA) is a stand-alone, web-based software tool that was used to perform a pharmaceutical analysis, an important step of the STRIP process. Data on diagnoses and current drug use (collected via SHiM and the actual medical record), recent measurements and laboratory values (e.g. renal function, blood pressure) and possible adverse drug reactions, as listed in the patient’s medical record and according to patient information (SHiM) were entered in STRIPA. The assignment of drugs to diseases has been implemented through a drag and drop mechanism.
DEDUCE [ Welzijn.AI | STRIPA | SNPCurator ]
DEDUCE is a pattern matching method for automatic de-identification of Dutch medical text. De-identification is done using fuzzy string matching and lookup lists. Validation shows generally good results, with a total micro-averaged recall of 0.916. For person names, a recall of 0.961 was achieved, missing no patient names. In followup research we compare DEDUCE with other de-identification methods such as Deidentify.
NB: DEDUCE is actively being used in various hosptitals in the Netherlands to deidentify clinical notes before access is granted as a mandatory part of the ethical approval procedure.
[ paper | benchmark ]
SNPcurator [ Welzijn.AI | STRIPA | DEDUCE ]
SNPcurator is a system for information extraction specifically in the genome wide and candidate genes studies, constructed out of different natural language processing (NLP) modules to aid scientists in their search for relevant disease-associated SNPs through an intuitive web interface. It incorporates both syntactic and semantic methods to extract relevant information from PubMed abstracts such as cohort size and ethnicity, SNP ids and the reported results.
